Web Scrapping using Python

Hello Coders!!
Do you spend a lot of time surfing on the internet to search for some data, which takes lots of effort and time? So web scrapper can be one of the solutions to this problem. In this blog article, I'll tell you how you can automate your research data from a website by making a simple web scraper using python.
In this blog, we will see:-
1. What is Web Scrapping
2. How Web Scrapers Work?
3. How to make a Web Scraper
What is Web Scrapping
Web Scraping is also called web data extraction or data scraping, is an automatic method in which we extract the web data in structured formate be it from the website or APIs. Many websites like Facebook, Twitter, Google give their APIs to the developer to use their data, which is structured formate but there are many sites that do not provide APIs, so their data is mainly unstructured in HTML format which is then converted into structured data in a spreadsheet or a database so that it can be used in various applications.
How Web Scrapers Work
Web scrappers can extract the data from the website or the data you want from any given URL. In this article, we will be scrapping indeed.com for the specific job profile for a specific location. For example, we will be looking for Python Developer Job in Mumbai. So let's get started.
First, we have to analyze the website how the website content is displayed on the webpage, the simplest way is to de inspect element for that page, on firefox and chrome you just right click and click on the option inspect Element or use the keyboard shortcut ctrl+shift+i.
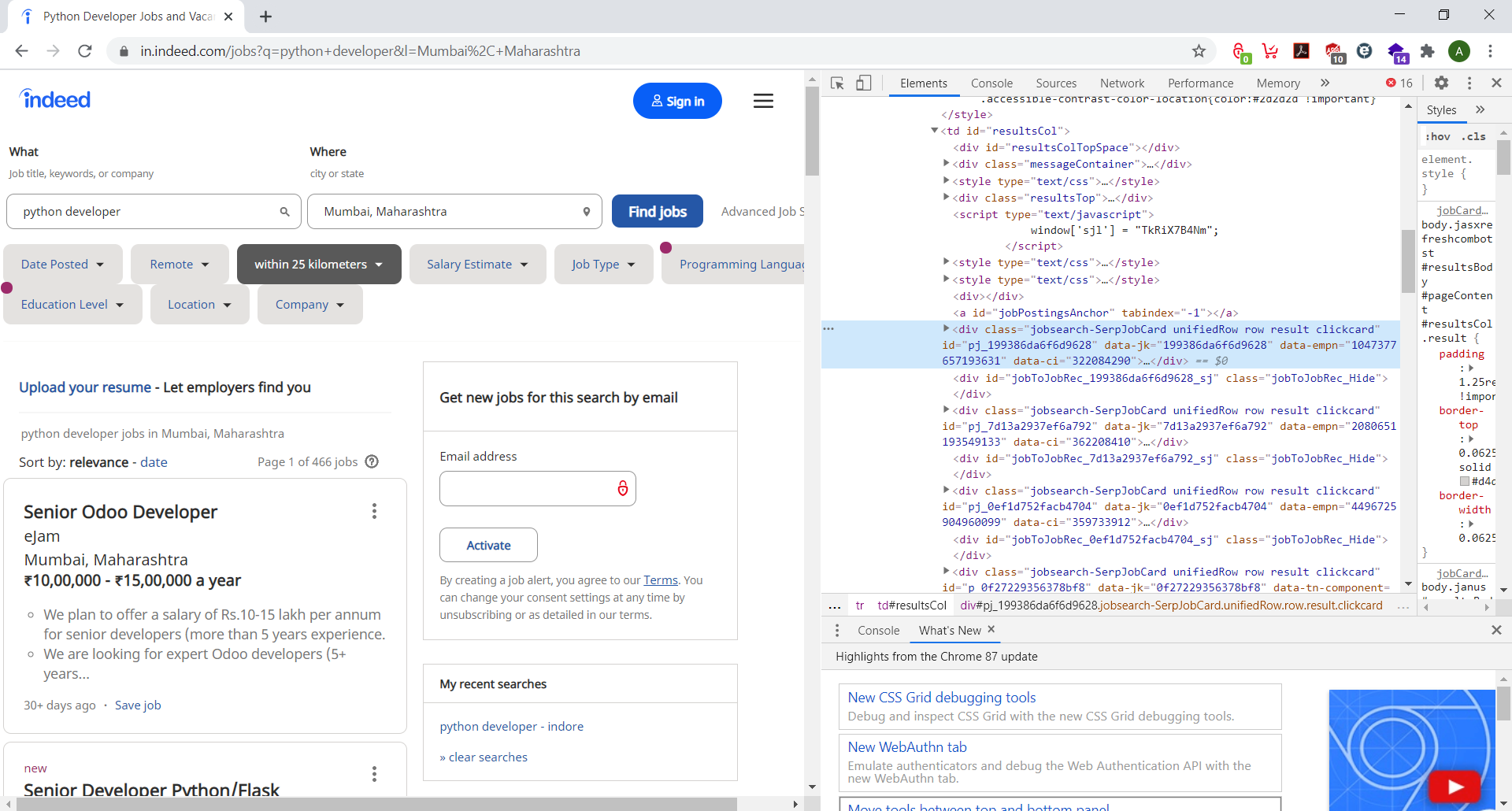
While analyzing the URL
https://in.indeed.com/jobs?q=python+developer&l=Mumbai%2C+Maharashtra
You can observe that our query ?q= is in URL with formate with job title python+developer with a separator & then the location as l=Mumbai%2C+Maharashtra.

Let's Begin our coding
We will require 3 python module requests, BeautifulSoup, and Pandas To download this module by following commands
pip install bs4 Pandas requests
Now as we have downloaded our modules lets import them as
import requests
from bs4 import BeautifulSoup
import pandas as pd
We will request the webpage with the URL
f'https://in.indeed.com/jobs?q=python+developer&l=Mumbai%2C+Maharashtra&start={page}'
where {page} is the page number of the site.
def extract(page):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
URL = f'https://in.indeed.com/jobs?q=python+developer&l=Mumbai%2C+Maharashtra&start={page}'
request = requests.get(URL, headers)
soup = BeautifulSoup(request.content, 'html.parser')
return soup
Now by this definition named extract(page), we will request for our URL where we have used our user agent which you can get through google by typing my user agent Now as the URL and Headers are set we will request the URL and pass the content which we will get to the BeautifulSoup so that, BeautifulSoup transforms a complex HTML document into a complex tree of Python objects, and return the soup variable to be used in other definition.
def transform(soup):
divs = soup.find_all('div', class_ = 'jobsearch-SerpJobCard')
for item in divs:
title = item.find('a').text.strip()
try:
salary = item.find('span', class_ = 'salaryText').text.strip()
except:
salary = ''
company = item.find('span', class_ = 'company').text.strip()
summary = item.find('div', class_ = 'summary').text.strip()
job = {
'title' : title,
'salary' : salary,
'company' : company,
'summary' : summary,
}
joblist.append(job)
return
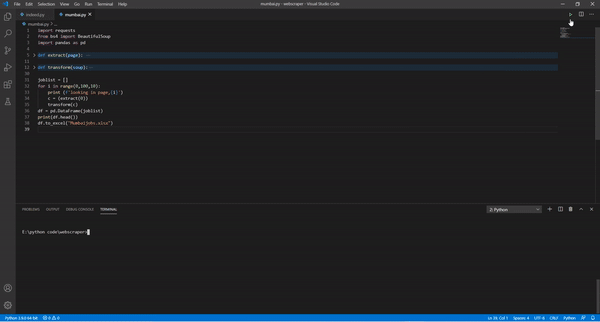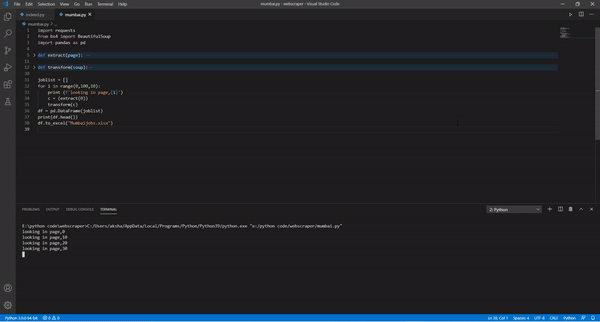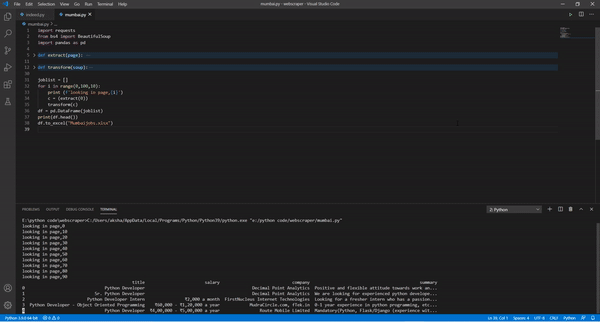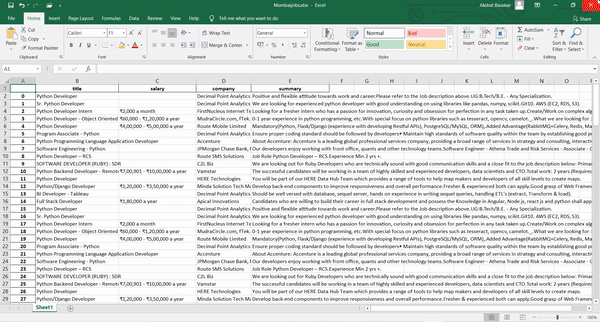
Now as we have the HTML content in the soup variable we will now extract the required data from the URL.
We will be focussing on mainly 4 things t extract from the webpage:-
- Title
- Salary
- Company
- Summary
In the definition named transform(soup) while checking thwe html content we found that the tile is stored in the div with the class name jobsearch-SerpJobCard within the a tag so we loop for all the items in div and extract all the a tag title content, salary is stored in the span with the class name as salaryText, but all job posting does not disclose the salary for this we have used try and except method so that it will leave the salary part for that job posting otherwise it will give an error if the class is not there for the salary part, Company is also stored in span with the class name as company and Summary is in the div with the class name as summary.
Then we just save data in the dictionary formate in a variable named data, and just append that dictionary to the joblist variable.
joblist = []
for i in range(0,100,10):
print (f'looking in page,{i}')
c = (extract(i))
transform(c)
df = pd.DataFrame(joblist)
print(df.head())
df.to_excel("Mumbaijobs.xlsx")
Here we have defined the list with variable joblist and to look on to every page we have used for loop with range 0-10 in the intervals of 10 (0,10,20.....) and then called our functions to extract and transform.
To make the dataframe we have used pands and make the excel file named mumbaijobs.xlsx
Follow me on Instagram techworld_security
Github repository for code Webscrapper.py

